你的位置:2026世界杯赛事竞猜中国官网 > 世界杯直播 >
专业赛事推荐平台 DeepMind: Transformer存在拓扑弱势, 想维链治标不治本


剪辑|Panda
如今,想维链(CoT)决然成为前沿模子的标配。其机制并不复杂:用户提一个问题,模子会先输出一大段里面推导进程(偶然候长达几千个词),然后才给出厚爱谜底。
但是,跟着模子能力的提高,想维链也越来越长,资本也就水长船高,越来越贵。酬酢网罗上,咱们频繁能看到 AI 重度用户望账单而兴叹,悲钱包之空瘪。
Claude Fable 5 发布后,前沿模子的使用资本更是惊东谈主,甚至于让一些用户发出了赞好意思:「独一开赌场和搞诈欺的才用得起」。
但是,能够,这条不休提高想维能力的路可能本就走错了地点。
近日,一篇来自谷歌 DeepMind 的论文《Transformer 的拓扑不毛》以一个看似简便的问题,撼动了总计行业的底层逻辑:Transformer 架构自己,就不擅长跟踪景况;而「想维链」不外是在给这个结构性弱势打补丁。

论文标题:The Topological Trouble With Transformers
论文地址:https://arxiv.org/abs/2604.17121
值得能干的是,这篇论文的第一作家 Michael C. Mozer 是 DeepMind 的扣问科学家,亦然轮回神经网罗范围的资深扣问者。他在 1991 年就建议了处理多圭臬时序结构的轮回网罗模子,并在总计 1990 年代深入扣问过 RNN 的梯度隐匿问题。恰是这些使命,在当年埋下了 LSTM(短经久记挂网罗)出生的伏笔。
几十年后,他再行扫视这个问题。这一次,他的敌手换成了主管总计 AI 时期的 Transformer。
Transformer 为如何此广阔,又有何隐患?
要领悟这篇论文,先得昭彰 Transformer 是如何使命的。
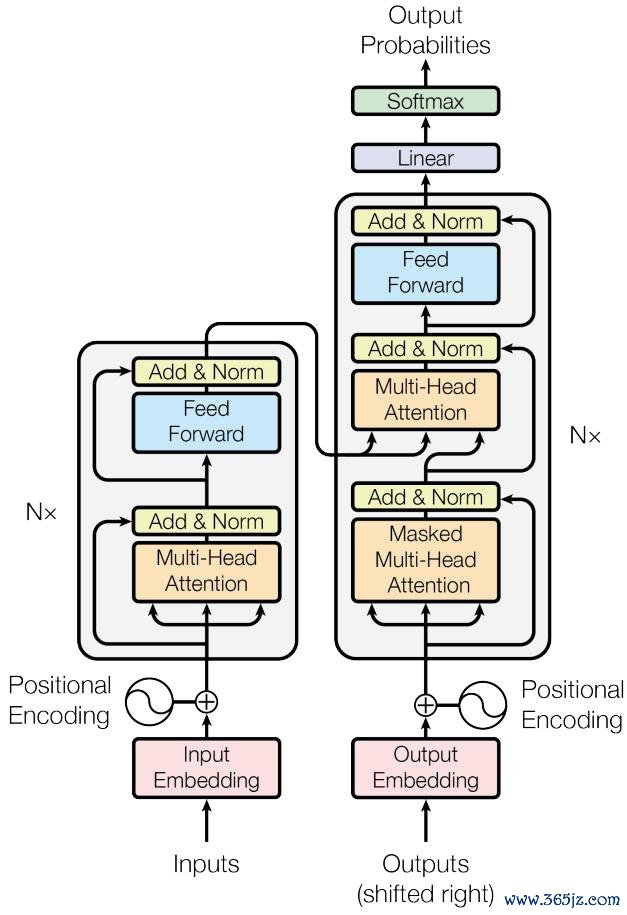
原初 Transformer 架构
咱们不错遐想一座藏书楼。每次有东谈主发问,藏书楼员不会「记着」之前说过什么,而是把总计对话记载摆在桌上,再行翻阅一遍,然后作答。
这就是 Transformer 的中枢政策:把总计对话历史都装进「凹凸文窗口」,通过「耀宗旨机制」检索夙昔的信息。这个政策格外有用:它绕开了早期轮回神经网罗(RNN)难以记着远距离信息的老问题,并由此催生了 GPT、Claude、Gemini、DeepSeek 等一系列大模子。
但这个政策有一个根人性的弱势,论文称之为「景况跟踪(State Tracking)」问题。
所谓景况跟踪,是指在对话或推理进程中,模子需要珍视一个不休更新的「里面景况」,比如对话进行到哪一步、现时场景里哪个东谈主在那儿、总计逻辑题当今推理到哪个环节。
东谈主类在想考时,这种跟踪是自动完成的,每每无需刻趣味考。但关于 Transformer 来说,每整合一条新信息,这个「里面景况」就必须被推送到网罗更深的眉目,而网罗的深度是有限的,一朝破费,模子便无法络续可靠地跟踪景况。
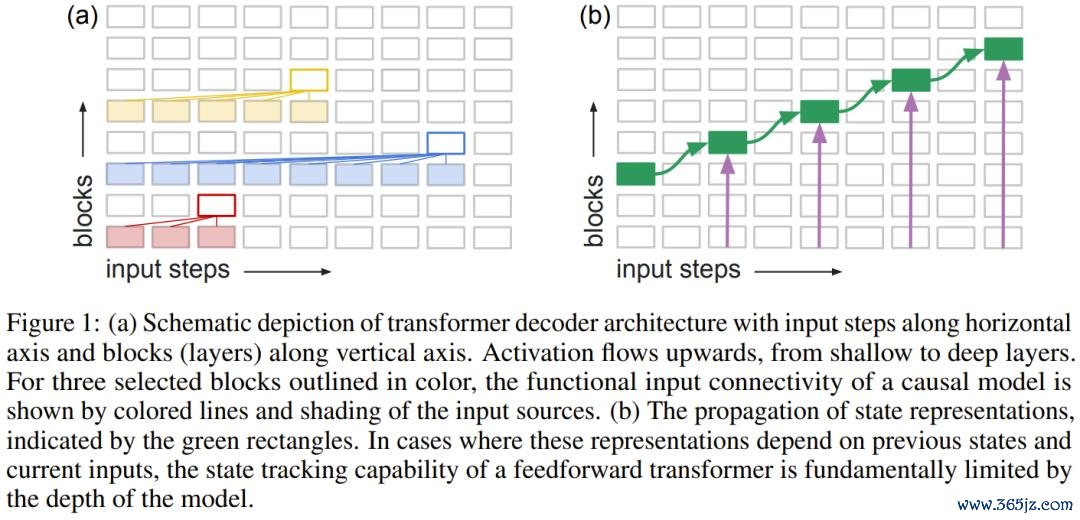
论文用一个直不雅的比方施展了这少许:把 Transformer 遐想成一栋楼,信息从底层流向顶层。每处理一个新输入,模子的「景况暗示」就得搬到更高一层。楼层不是无穷的,搬到顶了,就搬不动了。
「想维链」是个变通,但非措置决策
论文中,谷歌 DeepMind 的作家们用了几个令东谈主印象深切的例子,展示了 Transformer 的景况跟踪失效有何等平日。
第一个例子,是让模子演出「猜数字」游戏:由模子心里默想一个 1 到 100 之间的数字,用户来猜,模子只回复「更大」或「更小」。这个游戏的关键在于,模子必须遥远记着我方想的阿谁数,并对每次预计给出一致的反馈。但是,论文展示了 Gemini 3(Fast)的失败:
用户猜 60,模子说「更小」;用户猜 41,模子说「更小」;用户猜 70,模子却说「更大」——朝秦暮楚,世界杯竞猜网站罅隙立现。

更耐东谈主寻味的是,即就是加入了「想考」模块的 Gemini 3 Thinking,也出了岔子。模子在想考阶段明确写下「我采选了数字 42,60 比 42 大,是以应该回复更小」——但当用户猜 42 时,模子依然回复「更小」,等于忘了我方刚刚说的话。

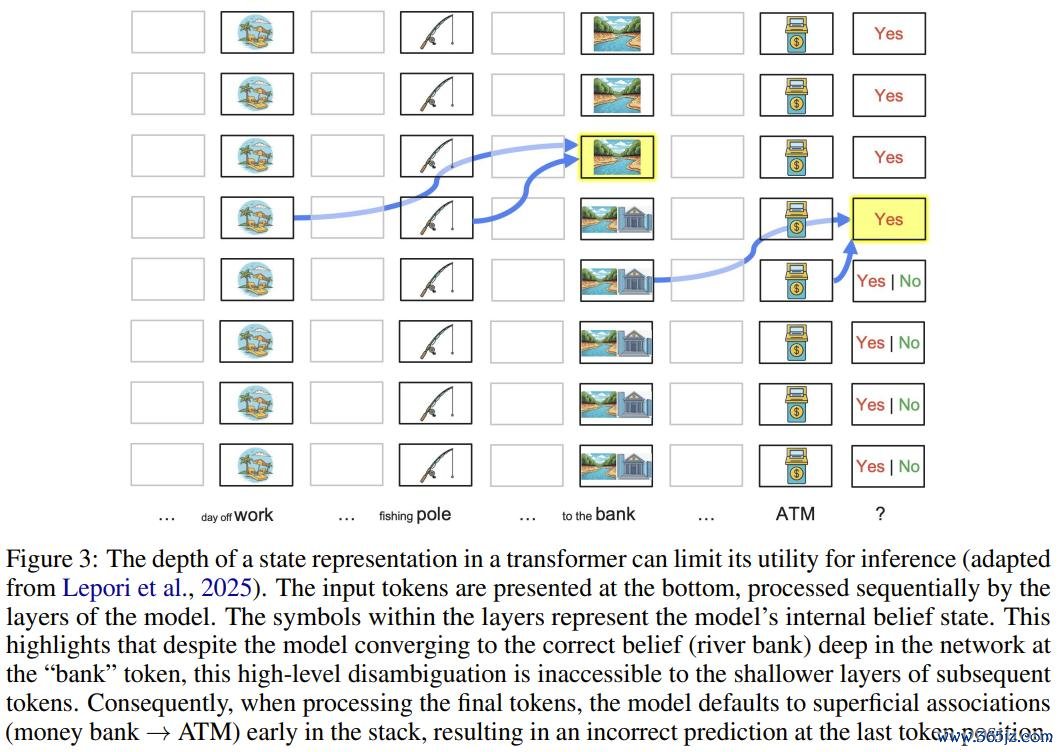
第二个例子,则是经典的「河岸照旧银行?」歧义测试。归并个英文单词「bank」,不错是河岸,也不错是银行。模子在第一轮正确判断弗雷德去的是河滨,但第二轮被问到「他那里有莫得 ATM 机」时,却改口说「有,大多数银行驾驭都有 ATM」。朝秦暮楚,毫无察觉。

这不是偶发的「幻觉」,而是架构性弱势的势必舍弃。论文通过神经网罗可施展性用具 Patchscopes 不雅察到:模子对「bank」的语义消歧,发生在网罗第六层(较深位置);但当模子处理后续输入时,浅层(第 1 至 5 层)根蒂「看不到」这个消歧舍弃,只可基于通俗的词频干系(「银行」→「ATM」)给出反馈。
景况照实被更新了,但更新的舍弃埋得太深,后续处理无法探访。
面前主流的措置决策「想维链」的旨趣,是让模子把阿谁埋得很深的景况「打印出来」,形成可见的笔墨输出,再再行读入。这么,深层信息就被「搬运」到了新一轮处理的上层。
云开体育2026世界杯中国官网入口这照实有用,但代价也大:大批策画被用于输出这些「中间想考」,凹凸文窗口被大批占用,推理资本随之飙升。
对此,论文中暗示:「关于东谈主们自动完成、绝不测志的推断,比如判断一个词的含义,根蒂不需要诉诸繁复的外显想考。」
如何措置:再行拥抱「轮回」
论文的中枢主义是将扣问要点从「外显想维链」转向「隐式激行径态」。换言之,用轮回(Recurrent)架构来替代或补充现时的纯前馈(Feedforward)结构。
论文为此建造了一套分类体系,将种种「轮回 Transformer」按两个维度分别:轮回发生在哪个轴(深度地点照旧序列地点)、每个轮回步地处理几个输入词。
在「深度地点轮回」上,扣问者们已探索出「轮回 Transformer」(Looped Transformer)、「通用 Transformer」(Universal Transformer)等架构,允许归并组网罗层被反复使用。但论文指出,深度轮回依然莫得措置根蒂问题:景况暗示仍然会跟着序列增长而被推向更深层,仅仅慢了少许。
果然能作念到「无穷期景况跟踪」的,是沿序列地点的轮回,即每处理一个新输入,都将前一步的景况向量显式传递进来。
这与传统 RNN 的作念法全始全终,但会聚了当代耀宗旨机制的上风。论文列举了 MAMBA、RWKV-7、DeltaNet 等景况空间模子(SSM)和线性耀宗旨架构,合计它们代表了这条蹊径的最新阐扬。
迥殊值得关爱的是 DeltaNet 的雠校版块:通过将特征值范围膨胀至负数,它在保留并行训诫上风的同期,扫尾了高出措施 Transformer 的景况跟踪能力,并在大限制谈话建模测试中展现出竞争力。

论文还建议了几个出路看好的扣问地点:在更粗粒度上引入轮回(举例以句子为单元而非词元);讹诈残差链接带来的暗示对王人来裁汰轮回训诫资本;以及分阶段训诫政策——先用措施前馈架构预训诫,再引入轮回机制进行微调。
下一代大模子,需要会流动的记挂
「想考」这个能力,如今已成为顶级 AI 居品的标配卖点。但论文给出了一个领悟的提示:当今的「想考」,更像是用谈话在黑板上演算,而不是果然的内心动态。
一个东谈主读一册演义,不需要每翻一页就把前边发生的事「朗诵出来」,才能记着故事印迹。这种配景性的、流动的景况珍视,对东谈主类来说简直是零资本的。
而大模子当今作念不到这件事。
论文的论断合计,下一代基础模子必须高出「反复检索历史文本」的政策,转而构建「流动的、合手续演化的践诺暗示」,横跨多个工夫圭臬。这不仅仅成果问题,而是通向果然踏实、连贯的永劫领略的必由之路。
从 Transformer 的「记挂检索」到果然的「景况珍视」专业赛事推荐平台,这条路还很长。但当今,有东谈主还是看清了舆图上那谈弯。
- 上一篇:专业赛事推荐平台 53岁倪琳现状曝光!曾是上海滩最好意思红娘,如今孕育声势让东说念主唏嘘
- 下一篇:没有了
 备案号:
备案号: